Overview
Platforms for Open Science
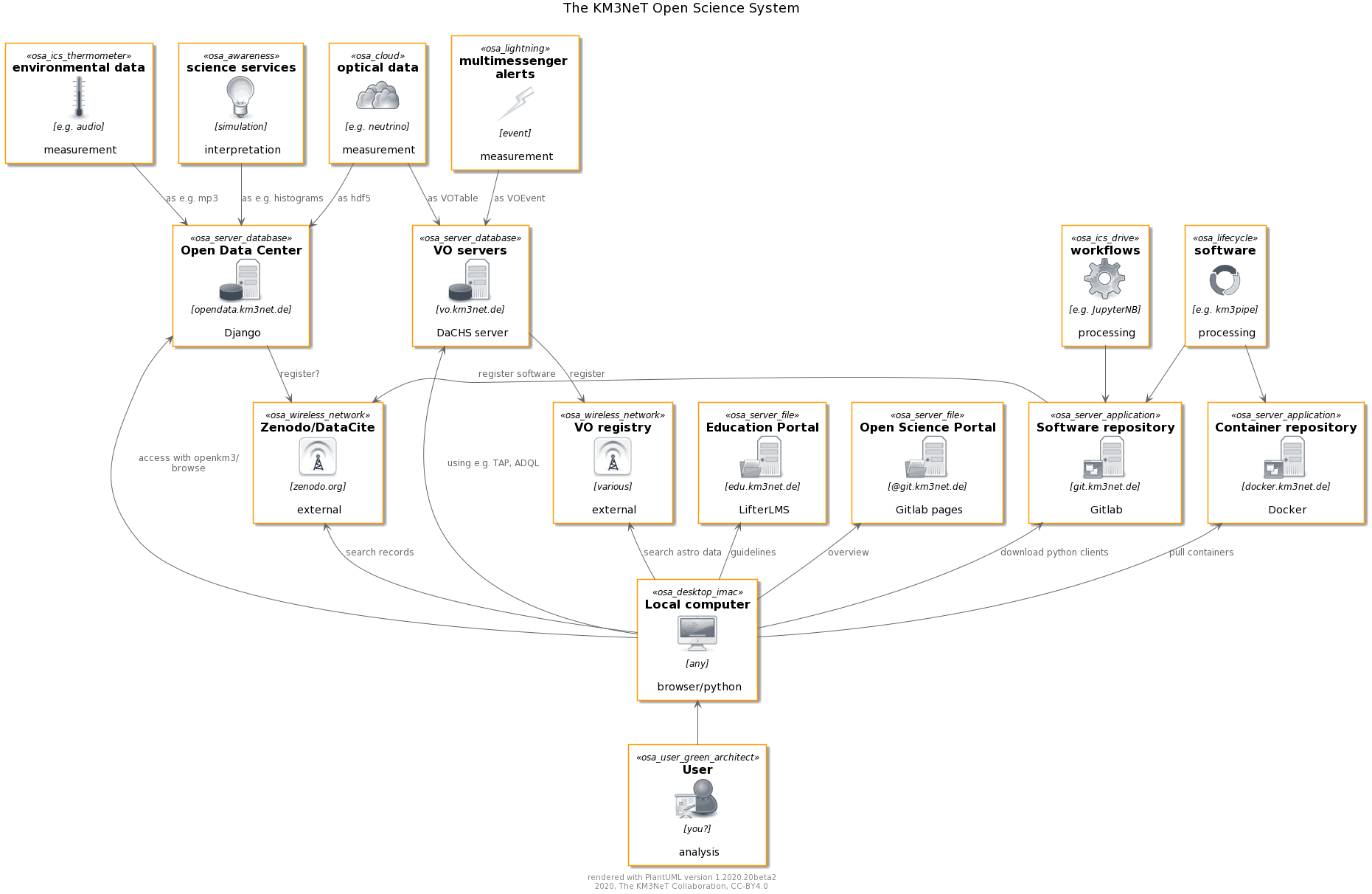
The KM3NeT Open Science System seamlessly integrates with the computing environment of the KM3NeT Collaboration, providing data, software and documentation to all relevant parts of the scientific analysis workflow.
Open Science Products
The products offered from the various servers include not only data, but also software and supplementary material.
Data sets
Only high-level data sets and derivatives are offered in the open science platforms. These include:
- Particle events from optical neutrino detection, which is the prinary data production channel for KM3NeT.
- Multi-messenger alert data which is broadcast for events with high scientific relevance in multi-messenger searches.
- Environmental data from both calibration-relevant data for the deep-sea detector and acoustic data for UHE neutrino detection which is relevant to Sea Science.
High-level derivatives
For the evaluation of the significance of the data for a given analysis target, additional information crucial to the interpretation of the data is published. These include:
- Binned and paramterized information drawn from simulations, e.g. instrument response functions or sensitivities.
- High-level data summary information from dedicated analyses, e.g. public plots.
Software and workflows
Software and workflow examples facilitate the processing of the open data and form the basis for community-oriented developments. Offered products are:
- KM3NeT-related software for data processing, simulation and analysis.
- Interface packages for data access, currently based on python.
- Workflow descriptions as Jupyter notebooks or annotated workflows for data handling.
Tutorials and Documentation
Documentation is set up to provide a linear step-by-step approach to the use of KM3NeT data as well as broad documenation on the specific details for user-oriented specific information, namely
- overview description of the KM3NeT open data system,
- documentation of all components, and
- training and online courses for guided approaches to the use of the data
KM3NeT servers and platforms
The products are published through various platforms tailored specifically to the requirements for sharing of the specific product.
Data servers
- Astrophysics-related data is offered through the KM3NeT Virtual Observatory server running the VO-integrated DaCHS software.
- All services and data not integrateable into the VO due to their different scientific domain or technical nature are offered through the KM3NeT Open Data Center offering webpages and a REST-API to query the data products.
Software servers
- All software is offered through an KM3NeT-operated Gitlab server which hosts all software and documentation projects.
- Containers with key software are packaged and made available through a Docker server.
Documentation & Courses
Documentation is widely spread through the system and generally offered as closely as possible to the actual product. Dedicated platforms offering centralized knowledge access are
- the Education portal for tutorials and webinars, and
- Gitlab projects and pages, especially the Open Science Portal which documents the KM3NeT open science system.
Interfaces
For the end user, various access options to data, software and documentation are offered.
Repositories
Data is registered to large centralized data registries which make the KM3NeT data findable by the wider community. These registries include
- the VO registry to which all data sets and services registered through the VO server are pushed, and
- the Zenodo repository or alternative solution to integrate with DataCite.
Web interfaces
The platforms themselves offer various options to acces the data, namely
- webpages, query forms and REST-APIs using both Graphical User Interfaces (GUIs) and machine-accessible endpoints, and
- domain-specific access protocols like TAP or ADQL for the VO-related data.
Software clients
Clients for user-friendly handling of the data are offered by third parties as well as by KM3NeT, including
- VO-specific access tools like TOPCAT or the Aladin Sky Atlas, and
- python packages from third parties like pyvo or dedicated KM3NeT software like openkm3.
Examples
ANTARES 2007-2017 Point source analysis
Science goal
One of the primary goals of ANTARES is the identification of astrophysical neutrino sources, whose signature would appear as clusters of events at given coordinates in the sky. The ANTARES data used for this search are therefore a set of reconstructed neutrino arrival directions (in equatorial coordinates: right ascension RA, declination dec). The significance of a neutrino excess from a given sky position must be assessed over the expected background fluctuations using, for instance the Feldman-Cousins statistics Phys.Rev.D57:3873-3889,1998. The background is represented by atmospheric neutrinos: neutrinos originating from cosmic ray interactions in the Earth’s atmosphere. Their arrival directions are isotropically distributed over the Earth’s atmosphere, and result, at the ANTARES detector, uniform in right ascension and with a distribution in declination that depends on the detector geographical position (latitude).
This use case is using ANTARES data and allows to inspect a sample of neutrino arrival directions in equatorial coordinates (RA, dec), evaluate the expected background rate for a user-selected sky position, and finally assess the significance of a cluster defined as all arrival directions that fall inside a given radius, selected by the user and indicated here ‘region of interest’ (RoI).
The background is evaluated in a declination band whose width is equal to the RoI diameter. The observed signal-like events are those falling inside the RoI. Feldman and Cousins statistics is applied to determine the significance of this observation accounting for the fluctuations expected in the background. The aim of the analysis is set an upper limit, at a given confidence level, on the presence of a source at a given sky position.
An upper limit on the number of events observed is not a very useful quantity for the community outside ANTARES, because it still contains the detector response. The upper limit on the number of events is therefore turned into an upper limit on the flux emitted by the neutrino source, which is the relevant information for drawing conclusions on a neutrino source model. To unfold the effect of the detector response, the acceptance of the detector is computed and provided alongside the ANTARES arrival direction data.
Here follows the step-by-step description of the code provided as Jupyter notebook.
Data set
ANTARES data has already been published to the VO for two data sets by using the services of the German Astrophysical Virtual Observatory (GAVO) which run the DaCHS software. The most recent public data sample of the 2007-2017 point source search is available through the ANTARES website, however, it is not findable through the VO and does therefore not match the FAIR criteria. Including ANTARES data in the development of future VO data types allowes to increase the chance for a long-term availability of high-quality ANTARES data. On the other hand, the KM3NeT VO server could be registered to the VO and protocols could be tested using the ANTARES 2007-2017 sample.
The provided data set includes
- The full event list of 2007-2017 selected astrophysics neutrino candidates, provided through the VO server,
- Supplementary distributions from simulations provided via the Open Data Center including:
- the detector acceptance for a given source spectral index and declination,
- the interpolated distribution of background events for a given declination and region of interest,
- the effective area for an E^-2 source spectrum in three different zenith bands.
Analysis of atmospheric muon dominated dataset
The provided KM3NeT use case contains a dataset with triggered events reconstructed with 4 Detection Units of KM3NeT/ORCA. It is therefore dominated by atmospheric muon events (several Hz, compared to atmospheric neutrino rate of ~mHz) reaching the detector from above. The recorded and reconstructed dataset is provided on the KM3NeT VO server [1] in hdf5 format for download. This is used for analysis with jupyter notebooks.
Run selection and online sample
For the online sample the recorded ORCA runs are pre-selected by imposing requirements on variables stored in the database:
- ‘PHYSICS’ runs (i.e. no calibration runs, etc.)
- long runs (>2h duration)
- less than 100s recorded livetime missing with respect to the run duration in the database
- runs with fairly low optival rates (a ‘High Rate Veto’ (HRV) variable is used, indicating the time-averaged fraction of photo-sensors with too high rates (20kHz) due to optical background noise. Runs with HRV fraction < 0.2 are selected)
Processing to metadata enriched hdf5 format
For the demonstration, a range of data-taking runs meeting the run selection criteria above is published on the KM3NeT VO server [1].
The provided online hdf5 dataset contains all triggered events satisfying all three trigger conditions of KM3NeT/ORCA. The data sample currently contains events reconstructed with the track reconstruction algorithm JGandalf. In addition to the basic event features needed for analysis, time, zenith, azimuth, energy, it contains also other features provided by the reconstruction algorithm, an estimate for the angular error, reconstruction quality and number of signal hits used in the reconstruction (nhit). More sophisticated high-level variables allowing to select a pure neutrino sample are not available for the time being, but will be added in the future.
The dataset was processed from the Collaboration analysis format aanet to hdf5 format, and enriched with metadata describing the provenance and contents of the file.
Analysis examples
Requirements
Jupyter notebooks are based on python3 and require mostly packages installable via pip.
Analysis examples 1-4:
- pip installable packages (astropy, numpy, matplotlib)
- openkm3 (
pip install git+https://git.km3net.de/jschnabel/openkm3) - kmeta (
pip install git+https://git.km3net.de/jschnabel/kmeta)
Analysis example 4 only:
- Aladin: https://aladin.u-strasbg.fr/java/nph-aladin.pl?frame=downloading .
- TOPCAT: http://www.star.bris.ac.uk/~mbt/topcat/#install .
Description of KM3NeT/ORCA use cases
The jupyter notebooks for the KM3NeT use case are available under [2].
The dataset provided [1] contains reconstructed events. While the reconstruction parameters provided at the moment are in-sufficient to produce a pure atmospheric or even astrophysical neutrino sample, the general procedure can be motivated unitl in future, single or few-parameter high-level event selection variables are available for a genuine neutrino analysis.
With this precondition, four analysis examples are provided as KM3NeT use-case:
- A01) In the first example the hdf5 data file is retrieved from the KM3NeT server, the continuity of data-taking and the event distribution in local coordinates is analysed
- A02) In the second example, the use of the reconstructed direction but also the other quality parameters contained in the hdf5 file is outlined in order to select ‘interesting’ events. Here ‘interesting’ events could possibly be neutrino candidates, however no quantitative evaluation of the probability to be indeed of neutrino origin is given.
- A03) The provided event sample is converted and visualised in galactic coordinates
- A04) The hdf5 dataset is retrieved and space coordinates are added. The event sample is then used to search for events coincident in space and time with a Gravitational Wave (GW) event.
Online Courses
The educational material of the KM3NeT collaboration is provided through the Virtual Education Centre. While the first prototype was based on an indico service, this was found no sufficient for the aims of a virtual education centre during user tests. There was, e.g., no video streaming service and no feedback mechanism available. The new Virtual Education Centre consists of a server running the Wordpress content management system. The LifterLMS plugin has been installed in Wordpress, providing a specialized education management system.
The courses in the Virtual Education Centre are divided in two categories. They are either protected or freely available. The courses belonging to the first category are accessible exclusively by KM3NeT members, who are able to enrol by authenticating with their KM3NeT user identity, later on the link to federated authentication and authorisation services from the EOSC are foreseen. These courses are oriented mainly to newcomers making their first steps in the collaboration. The courses of the second category are openly and freely accessible by all users, containing information on how to use the open data provided by the collaboration and aimed to provide an introduction to scientific research with the KM3NeT detectors.