Making data FAIR
Requirements for FAIR data
The widely-accepted paradigm for open science data publication requires the implementation of the FAIR principles for research data. This involves the
- definition of descriptive and standardized metadata and application of persistent identifiers to create a transparent and self-descriptive data regime,
- Interlinking this data to common science platforms and registries to increase findability,
- possibility to harvest from the data through commonly implemented interfaces and
- definition of a policy standard including licensing and access rights management.
In all these fields, the standards of KM3NeT are currently developing. In this development process, the application of existing standards especially from the astrophysics community, the development of dedicated KM3NeT software solutions and the integration of the KM3NeT efforts developed during the KM3NeT-INFRADEV are integrated into the ESCAPE project, which forms the main development environments for open data publication in KM3NeT.
Compliance with the FAIR principles
The FAIR principles provide a solid set of requirements for the development of an open data regime. Following the FAIR requirements, the following solutions have been established in KM3NeT to enable FAIR data sharing and open science.
Findable data
- Unique identifiers have been defined for digital objects within KM3NeT, including data files, software, collections and workflow steps, as well as identifiers for relevant data sets like particle detection (“event”) in the detector.
- At the publication level, extended metadata sets are assigned to each published data product.
- The datasets can both be accessed via UID directly on the data servers as well as through external community-relevant repositories.
Accessible data
- The data can, at this point, be directly accessed via a webpage and through a REST-API where data cannot be offered through VO protocols.
- At this point, no authentication is implemented, although in the future an authentication scheme is aimed for to allow access to unpublished data sets for a associated scientists.
- Records will be kept and transfer to long-term data repositories for high-level data sets is envisioned for archiving.
Interoperable data
- Vocabularies and content descriptors are introduced that draw on external standards like VO standards or W3C standards where possible.
- Documentation on the metadata and vocabularies are provided.
- Metadata classes are well-connected to allow the cross-referencing between different digital objects and extended metadata.
Reusable data
- Licensing standards for data, software and supplementary material have been introduced.
- Basic provenance information is provided with the data, which serves as a development start point to propagate provenance management through the complex data processing workflow in the future.
Datamodels
Metadata definition lies at the core of FAIR data, as it governs both the understanding of the data and as well as the interoperablity through access protocols. While some software can be used almost as-is, especially regarding the well-developed interfaces in the Virtual Observatory, the different data types and science fields that KM3NeT can link into requires a flexible approach and diverse application of software. In order to meet these various requirements, metadata and class definitions are developed within KM3NeT, drawing on well established standards e.g. of the W3 Consortium, scientific repositories or the IVOA standards.
Data published via the KM3NeT Open Data Center (ODC) is annotated as KM3OpenResource, which includes basic metadata for resource content, accessibility and identification. As resources can be provided either as part of a collection, e.g. data set or multiple resources related to an analysis, or as part of a stream of similar objects, e.g. of alert data, resources are grouped in the server as KM3ResourceCollection or KM3ResourceStream to facitlitate findability. Further details on these first data classes are documented in a developing Git project. In the future, further classes will be introduced and adapted governing e.g. the scientific workflow as discussed in the according section.
Resource description
The KM3OpenResource class serves as base class to describe any KM3NeT open resource, be it a plot, dataset or publication. The information gathered here should be easily transformable to publish the resource to repositories like the Virtual Observatory or Zenodo based on DataCite. As resource description metadata is widely based on standardized formats like the Dublin Core standard, the KM3Resource class picks the relevant entries from the resource metadata, including the VO Observation Data Model Core Components regarding the metadata specific to the scientific target, and the VOResource description and Zenodo resource description for general resource metadata.
Identifiers and content description
Identifiers serve to uniquely address digital objects. While Digital Object Identifiers (DOIs) are of long-standing use in the scientific community, these public identifiers have to link to an KM3NeT-internal identification scheme which allows to back-track the data generation and link between various data products related to a scientific target or publication. In addition to this, an ordering schema for class definitions and content descriptors helps in the interpretation of a specific digital object. To this end, the ktype and kid have been introduced.
kid
The kid is a unique identifier which follows the uuid schema. The uuid is ideally assigned at the generation of the digital object where possible and stored in the metadata set or header of the digital object. It is the goal to use kid assigment at all steps of data processing and has been implemented for all open science products.
ktype
The ktype serves as a content descriptor and is defined as a string with a controlled vocabulary of words separated by “.”, starting with “km3.”. The selected vocabulary comprises domain names, class and sub-class names and, in some cases, identifiers for class instances, like
km3.{domain}.{subdomains}.{class}.{subclasses}.{instance}
e.g. “km3.data.d3.optic.events.simulation” for a data set of processed optic event data (data level d3) from Monte Carlo simulation, indicating a file class, or “km3.params.physics.event.reco.reconame.E” indicating the parameter definition of the reconstructed energy of particle events from a reconstruction algorithm named “reconame”.
Particle event identifiers
For various elements of data taking, identifiers are used to uniquely label e.g. different settings of software and hardware or annotate data streams. At the data aggregation level, an identifier therefore has to be introduced to uniquely identify a particle detection in one of the KM3NeT detectors.
Due to the design of the data acquisition process, these events can be uniquely identified by
- the detector in which they were measured, assigned a detector id,
- the run, i.e. data taking period during which it was detected, assigned a run id,
- the frame index, indicating the numbering of the data processing package in the DAQ system on which the triggering algorithms are performed and
- the trigger counter, i.e. the number of successes of the application of the set trigger algorithms.
The internal KM3NeT event identifier is therefore defined as
km3.{detector_id}.{run_id}.{frame_index}.{trigger_counter}
Platforms and Servers
The Virtual Observatory server
The Virtual Observatory environment facilitates data publication and sharing among astrophysics community according to the standards set by the IVOA. The VO protocols implement the FAIR data principles and ensure an environment for better scientific use and public access to data from astrophysical experiments.
Dedicated software and exchange protocols are set up at participating data centers and tailored user programs grant easy user access to the diverse data through standardized labeling and description of the data. The KM3NeT collaboration is a data provider to the VO and operates a data server at http://vo.km3net.de/, running the (DaCHS software)[http://docs.g-vo.org/DaCHS/].
Implementation
Software package
The GAVO Data Center Helper Suite (DaCHS) is a “publishing infrastructure for the Virtual Observatory, including a flexible component for ingesting and mapping data, integrated metadata handling with a publishing registry, and support for many VO protocols and standards”. It can be applied for KM3NeT purposes “as is” and allows to various types of data and formats to the VO.
Standards for metadata Entries to the VO registry are annotated using the Resource Metadata standards of the IVOA. This metadata is required for publication. In the KM3NeT open science system, the KM3OpenResource class used to label all resources contains also entries which can be matched to the VO metadata standards, facilitating an automatic casting of the standard KM3NeT internal data format to the VO metadata.
Data conversion and upload
Format conversion
In order to transform event-based data to a VO-compatible format, standard scripts have been set up to convert neutrino event tables and the according metadata into VO-compatible format and add the required metadata to the data set. To publish a dataset, the procedure includes
- labeling the data set according to VO standards with information about origin, authorship, parameter formats and standardized event identifiers. In the DaCHS software, this is handled through a resource description file, to which information from the KM3OpenResource description is cast.
- Selection of the service interface, i.e. the protocols which are offered through the various endpoints of the server to the Virtual Observatory. This interface is also defined in the resource description.
Publication procedure
Publication involves uploading and listing the data set as available in the registry of the server, which is handled through simple administration commands in DaCHS.
Interlink to registries
In order to declare the entries of the local server to the IVOA Registry of Registries, the KM3NeT collaboration registered the server, obtaining a IVOA identifier (ivo://km3net.org) used in the VO context to
Example data
As KM3NeT does not produce astrophysics data yet, an alternative data sample from the ANTARES experiment was used to set up the system. The ANTARES collaboration has already published two data sets to the VO by using the services of the German Astrophysical Virtual Observatory (GAVO) which runs the DaCHS software and is maintainer of it. The most recent public data sample was only made available through the ANTARES website and thus did not match the FAIR criteria. Using the ANTARES 2007-2017 point source neutrino sample, the KM3NeT VO server could be registered to the VO and hosts this data set as example data.
Data access
Tabulated high-level neutrino event data can be accessed utilizing access protocols like the Table Access Protocol (TAP) and query languages like the Astronomical Data Query Language (ADQL). To query these data sets related to astronomical sources, the Simple Cone Search (SCS) protocol allows to pick specific events according to particle source direction.
The KM3NeT Open Data Center
For all data not publishable through the IVOA, the KM3NeT Open Data Centre is serving as interface and/or server to the data. For the setup of this server, the Django framework was used.
Implementation
Software package
Django is a python-based free and open-source web framework that follows the model-template-views (MTV) architectural pattern. Models implement e.g. the KM3OpenResource description, which serves as basic data description class. Templates allow the display of the information through views, which are accessible via webbrowser. In addition to this, REST API endpoints can be defined to allow managing and querying the data through web requests. It also offers an admin interface which allows manual adaption of the data via the GUI, and media storage which can serve to hold smaller data sets, along with a broad gallery of functions for url handling, testing, model description etc.
Standards for metadata
For the django server, which primarily serves as an interface to hold metadata for open science products, the metadata can be freely defined, and will develop with time depending on the requirements of the science communities the data is offered to. At this point, the models used by the server consist of the following three classes:
-
KM3OpenResource describes each registered data element, independent of the actual type of data. It holds metadata on the publication, the content and link to a description of the content, various optional identifiers like DOI in addition to the km3net identifier (kid), a link to the storage location of the actual data and metadata on data acess.
-
KM3ResourceCollection holds and describes links to several KM3OpenResources via their kid, and adds information on the collection. Resources of different kinds can be combined here, indicating e.g. that they belong to the same research object, e.g. the same analysis.
-
A KM3ResourceStream is used to group resources of the same type in a collection that can be extended by new resources by time. These resources are automatically updated from the defined urls.
Data conversion and upload
Format conversion The conversion of the data to be uploaded to the server or simply registered as KM3OpenResource was described in the section on data sets.
Publication procedure The publication procedure involves upload of the data to the server, and adding the resource description to the database. If the data product does not yet have a kid assigned, a kid is added to the resource. With this step, the data is made publicly available.
Additional features
The ODC will also be used to store metadata indepent of the publication of the data. It includes e.g. a kid search endpoint to allow to draw the metadata on any digital object registered with the server. This will allow to collect information e.g. on storage location of files and their descriptions. This serves as an interim solution to further the development of e.g. a full workflow management scheme.
Registries and Archiving
Registering the KM3NeT open science products with well-used platforms and assigning global identifiers is a key to findability of the data. As several KM3NeT servers (VO server, Open Data Center, Gitlab server) currently hold key data and software, products from these servers must be linked to larger platforms, ideally through semi-automatic integation. Also, at the end of the experiments, these products must be transferable from KM3NeT-hosted platforms to external repositories that ensure a longer lifetime of the digital products.
Virtual Observatory Registry of Registries
Registry structure
In the VO, the KM3NeT server is registered as a registry of resources, i.e. of the datasets and services offered by the server. The IVOA Registry of Registries (RofR) is a service maintained by IVOA that provides a mechanism for IVOA-compliant registries to learn about each other, being itself a compliant publishing registry which contains copies of the resource descriptions for all IVOA Registries. When a resource metadata harvester harvests from these publishing registries, they can discover all published VO resources around the world.
Identifiers
The KM3NeT VO server is registered with the following metadata to the RofR:
- name: KM3NeT Open Data Registry
- IVOA Identifier:
ivo://km3net.org/__system__/services/registry - OAI service endpoint: http://vo.km3net.de/oai.xml
With this registration, KM3NeT data in the VO is fully findable within the Virtual Observatory, and each resource is identifiable through the naming of the individual endpoint of the service within the registry.
Archiving
At the end of the operation of KM3NeT and, in case the server can no longer be operated, various national organizations in the KM3NeT member states offer long-term supported repositories, to which the data sets could be transfered. As example, the GaVO Data Center provided by Zentrum für Astronomie Heidelberg on behalf of the German Astrophysical Virtual Observatory already hosts other ANTARES data sets and is provider of the DaCHS software used in the KM3NeT VO server, so transfer for archiving would, at least from the current day’s perspective, be easy to achieve.
DataCite and Zenodo
Universal citation of data and digital objects is generally handled through assignment of a Digital Object Identifier (DOI), a persistent identifier or handle used to identify objects uniquely which standardized by the International Organization for Standardization (ISO). The VO does support the integration of a DOI in their resource metadata, but does not provide an authority to assign DOIs, as the organization assigning a DOI generally also has to host the data to ensure the longevity of the data resource.
This leads to the dilemma that either the KM3NeT collaboration would have to become a member organization to e.g. DataCite, a global non-profit organisation that allows the assignment of DOIs to its member organizations, and operate a repository, or copy or mirror data to another repository in order to get a DOI. While this issue is not yet resolved and will be investigated further also in the context of the ESCAPE project, where basic considerations are taken with respect to the EOSC, currently the second option is chosen for the small amount of data that is currently provided in this demonstrator. As hosting repository, Zenodo was chosen as well-established data repository in the physics community.
Registry structure
Zenodo was initiated by the OpenAIRE project and is hosted by CERN to offer a respository for research funded by the European Commission. It hosts publications, audio and visual media, software and datasets. It allows to create “communities” to group various resources, which has been used to create a KM3NeT community. Upload can be managed through an API as well as through a web interface and standardized metadata is required.
Identifiers
Zenodo assigns DOIs to resources on upload if a DOI cannot be provided, making the dataset also easily citable. For this demonstrator, the event sample from the KM3NeT ORCA use case (“one week of ORCA”) will be registered with Zenodo.
Archiving
As Zenodo offers long-term support of its resources and the data is already mirrored to the repository, archiving of the data can easily be accomplished.
Software integration
Github, Zenodo and pypi
With Github, a major platform exists for software development that also allows easy interaction between software developers on various projects. Open KM3NeT software is mirrored to Github, making the software findable for software developers. For grouping of the software, a KM3NeT collection has also been established here.
For python-based software, easy installation via the pip package installer is integrated to the software packages. This installer links to the Python Package Index (PyPI), a repository of software for the Python programming language. Here, a KM3NeT user account has been established to group and administrate the software.
Identifiers
Neither Github nor PyPI make software citable in the strict sense, as they do not assign DOIs. However, Zenodo allows the integration of Github repositores to their platform. Therefore, the combination of mirroring software to Github, making it installable via PyPI and registering it with Zenodo makes the software accessible for community development, easily installable for users and citable in a scientific context.
Archiving
Both PyPI and Zenodo copy the relevant software to their platforms, copies of the source code are stored at multiple sites and make archiving easy.
Data Quality assessment
The processes involved in the KM3NeT data processing chain can be grouped into a few main categories. Although the ordering of these categories is not strictly hierarchical from the point of view of data generation and processing, in the context of a general discussion one could safely assume that a hierarchical relation exists between them. From bottom to top, these categories would be data acquisition, detector calibration, event reconstruction, simulations and finally scientific analyses based on the data processed in the previous categories. The quality of the scientific results produced by KM3NeT will be affected by the performance of the different processes involved in the lower levels of the data processing chain. In order to implement a complete and consistent set of data quality control procedures that span the whole data processing chain, it is required to have a complete, unambiguous and documented strategy for data processing at each of the aforementioned process categories. This includes the setting of data quality criteria which should be initiated at the highest level of the data processing chain, and propagated towards the lowest levels. For each of the aforementioned categories there exists a working group within the KM3NeT collaboration, in which a quality strategy is required and in the process of being established. It is therefore not possible to provide a full setup for data quality control at this point. Nevertheless, there have been copious software developments devoted to quality control along the different stages of the data processing chain. In the following, a description of some of the existing quality control tools and procedures is given. This description could be conceived as an incomplete prototype for a data quality plan. The implementation of these procedures into an automated workflow requires the design and implementation of a standardised data processing workflow which meets software quality standards. This does not exist either. Some of the figures and results shown here have been produced ad-hoc, and not as a result of any working system.
Data quality control procedures
Online Monitor
During the data acquisition process, the online monitoring software presents real time plots that allow the shifters to promptly identify problems with the data acquisition. It includes an alert system that sends notifications to the shifters if during the data taking, problems appear that require human intervention. The online monitor uses the same data that are stored for offline analyses (this is actually not true, and should be changed). This implies that any anomaly observed during the detector operation can be reproduced offline.
Detector Operation
As explained in the detector section, the optical data obtained from the detector operation are stored in ROOT files and moved to a high performance storage environment. The offline data quality control procedures start with a first analysis of these files which is performed daily. It mainly focuses on but is not restricted to the summary data stored in the ROOT files. The summary data contain information related to the performance of the data acquisition procedures for each optical module in the detector. As a result of this first analysis, a set of key-value pairs is produced where each key corresponds to a parameter that represents a given dimension of data quality and the value represents the evaluation of this parameter for the live-time of the analysed data. The results are tagged with a unique identifier corresponding to the analysed data set and uploaded to the database. In the present implementation the analysis is performed for each available file where each file corresponds to a data taking run, although this may change in the future as the data volume generated per run will increase with the detector size.
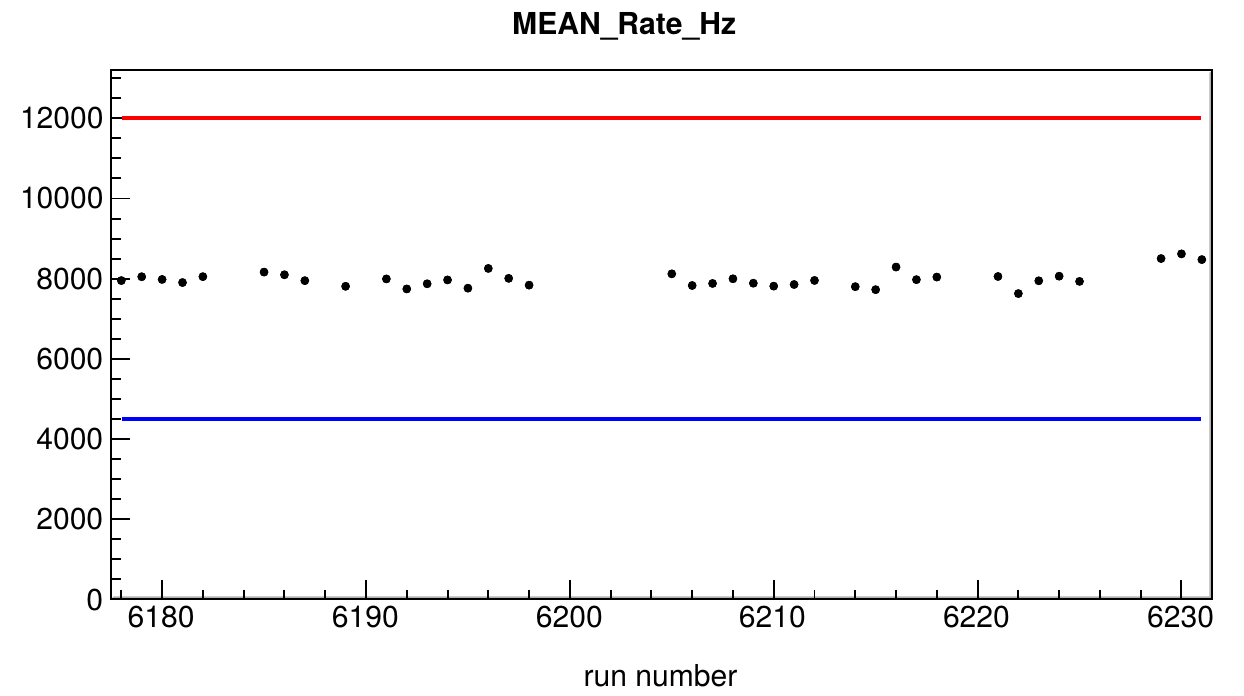
A further analysis of the results stored in the database includes the comparison of the values of the different parameters to some reference values, allowing for a classification of data periods according to their quality. The reference values are typically set according to the accuracy with which the current detector simulations include the different quality parameters. In addition, the evolution of the different quality parameters can be monitored and made available to the full collaboration as reports. Currently this is done every week by the shifters, and the reports are posted on an electronic log book (ELOG). The figure above shows an example of the time evolution for a quality parameter during the period corresponding to the data sample that are provided together with this report. The selected runs correspond to a period of stable rates and during which the different quality parameters were within the allowed tolerance.
Calibration
The first step in the data processing chain is to determine the detector calibration parameters using the data obtained from the detector operation. These parameters include the time offsets of the PMTs as well as their gains and efficiencies, the positions and orientations of the optical modules. The PMT time offsets and the positions of the optical modules are used in later stages of the data processing chain for event reconstruction, as well as by the real time data filter during the detector operation. While the event reconstruction requires an accurate knowledge of these parameters, the algorithms used by the real time data filter depend rather loosely on them, and its performance is not dependent on variations occurring within a timescale of the order of months. Nevertheless, it is still necessary to monitor them and correct the values used by the data filter if necessary.
The performance of the detector operation also depends on the response of the PMTs, which is partly determined by their gains. These evolve over time, and they can be set to their nominal values through a tuning of the high-voltage applied to each PMT. Monitoring the PMT gains is therefore also necessary to maximise the detector performance. Additionally, the PMT gains and efficiencies are also used offline by the detector simulation. Within the context of data quality assessment, software tools have been developed by KM3NeT that allow to monitor the parameters described above and to compare them to reference values, raising alerts when necessary. The reference values should be determined by the impact of mis-calibrations on the scientific results of KM3NeT, a task which at this point has been started to be addressed. The arrangement of these tools into a workflow requires the elaboration of an underlying calibration strategy. This has not been done, and the work is therefore on hold.
Simulations and event reconstruction
Once the calibration constants have been determined, the data processing chain continues with the event reconstruction, and with the simulation and reconstruction of an equivalent set of events where the information in the summary data is used to simulate the data taking conditions. The simulation of particle interactions and propagation is done by dedicated software, while the detector simulation and event reconstruction is done by Jpp. As a result of the simulation chain, a ROOT file is obtained which has the same format as the ROOT file produced by the data acquisition system. This contains events obtained after the simulation of the detector trigger. The resulting file and the corresponding data taking file, are identically processed by the reconstruction software, which produces ROOT formatted files with the result of reconstructing the real data events and the simulated events respectively. The comparison between data and simulations is an important parameter to measure the quality of the data and it can be done at trigger level, and at reconstruction level.
In both cases, the comparison follows the same strategy: the root files are used to produce histograms of different observables and these histograms are saved into new ROOT files. A set of libraries and applications devoted to histogram comparisons have been developed in Jpp. These implement multiple statistical tests that can be used to determine if two histograms are compatible, as well as the degree of incompatibility between them. Additionally, tools have been developed that allow to summarise the results into a number per file, which represents the average result after comparing all the observables. For the example provided here, the discrepancy between data and Monte Carlo is measured through the calculation of the reduced χ2 for each observable, and the summary is given as the average reduced χ2 of all the compared observables for each file. The following figures show the value of this parameter for the data and simulations comparisons at trigger and reconstruction levels.
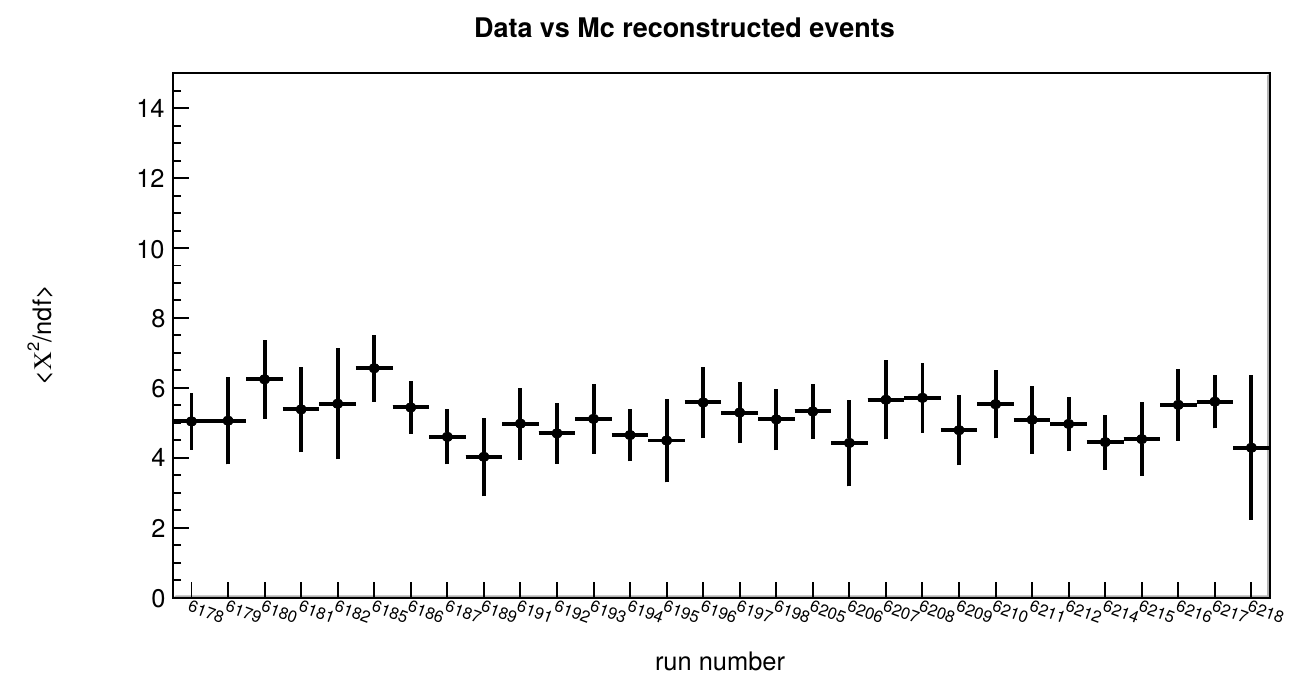
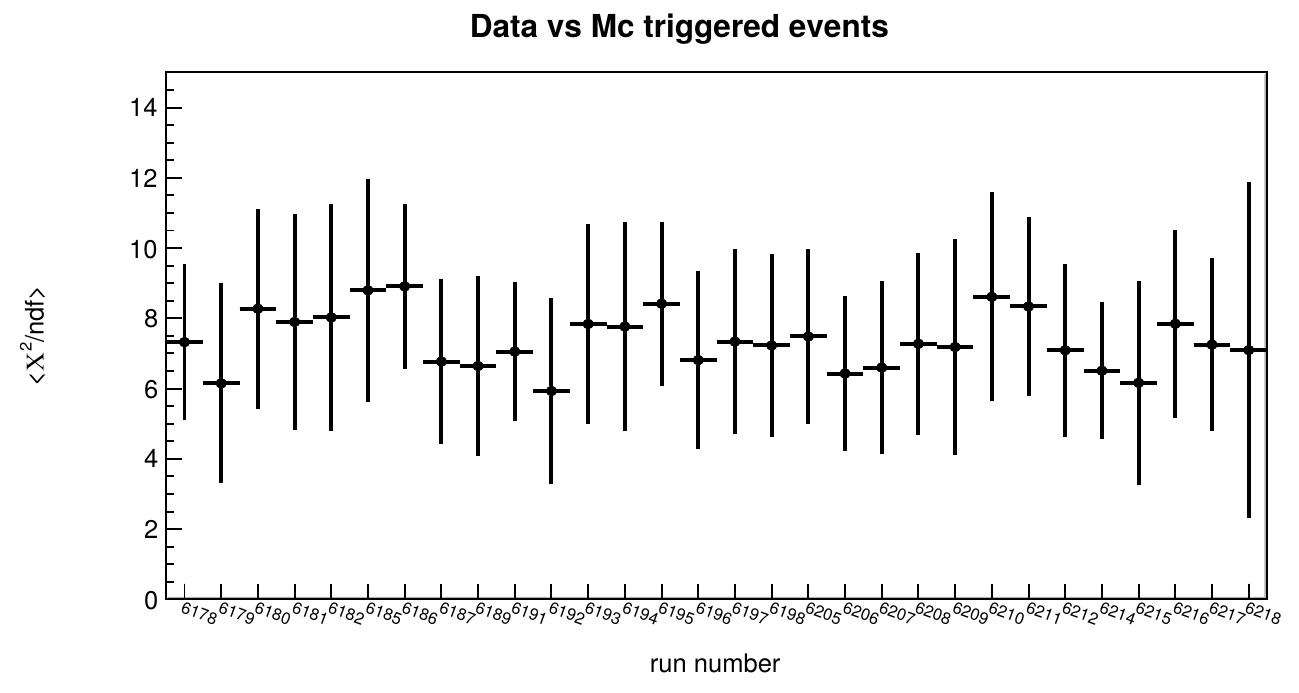
These tools would also allow for the calculation of other data quality metrics by comparing the data with figures of merit for different observables. For this, the development of plans and strategies mentioned in the introduction of this section is necessary. The contents in the files produced by the reconstruction routines are the main ingredients for the physics analyses, though these analyses are typically done with dedicated software frameworks which require a special formatting of the data. The data format used for physics analyses is called ‘aanet’ format, which is also based in ROOT. Control mechanisms are thus needed to ensure consistency between the files produced by Jpp, and the aanet formatted files. Consistency between Jpp and aanet files can be verified up to a certain level by producing distributions of the different parameters and by verifying that these distributions are identical.
Copyright and Licensing
Find more infos here